On April 16, 2026, Anthropic quietly shipped the model that most developers actually asked for.
Not Claude Mythos — the "too dangerous to release" research preview locked behind an enterprise waitlist. The one you can type into Claude.ai right now, or point your Cursor at, or bill on AWS Bedrock. Claude Opus 4.7.
The marketing is muted. The numbers are not.
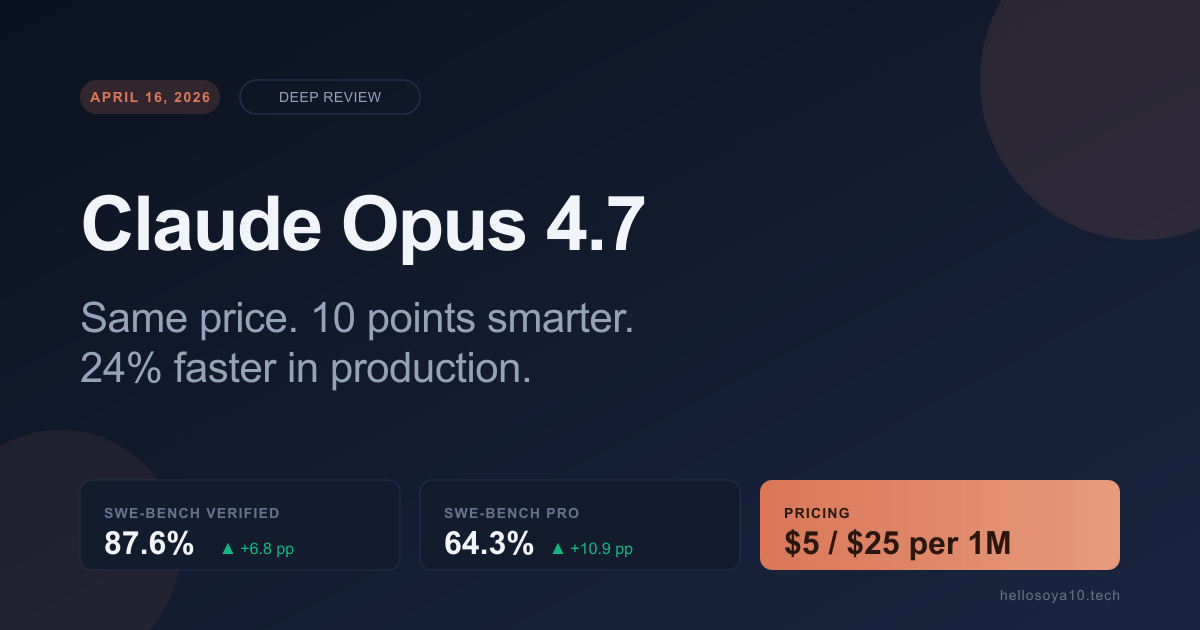
On SWE-bench Pro — the harder agentic-coding benchmark — Opus 4.7 resolved 64.3% of tasks, up from 53.4% on Opus 4.6. That is a 10.9 point jump. On SWE-bench Verified, it hit 87.6%, retaking the lead among generally-available models. And Box, one of the first enterprises with data to share, reports a 56% reduction in model calls and a 24% speedup on real production workflows — at the same $5/$25 per million token price.
That last part is the real story. Opus 4.7 is not just smarter. It is cheaper to run for the same outcome, in ways that don't show up in the rate card.
Here is what changed, what to watch for, and whether you should migrate today.
What Actually Changed in Opus 4.7
Three concrete shifts, in order of how much they'll affect your bill:
1. It writes its own tests before calling the task done. Opus 4.7 has a new self-verification loop baked into agentic coding. Instead of producing a patch and waiting for you to run the test suite, it now writes verification steps, runs them against its own output, and iterates on failures before surfacing results. In practice this means fewer round-trips, fewer "that didn't work, try again" conversations, and fewer wasted tokens on the human side.
2. Vision got 3.3× more pixels. Maximum image resolution jumped from 1,568 px to 2,576 px on the long edge, moving from roughly 1.15 megapixels to 3.75. If you've been downscaling screenshots, wireframes, or dashboards before uploading, stop. Opus 4.7 also hits 98.5% on visual-acuity benchmarks, up from 54.5% on 4.6. That is a category change, not an increment.
3. Long-running agents finally work. Anthropic rebuilt how Opus maintains context across sessions and launched "task budgets" in public beta on the API, letting you cap token spend on a per-task basis. For multi-hour agent runs, this is the first time pricing is predictable.
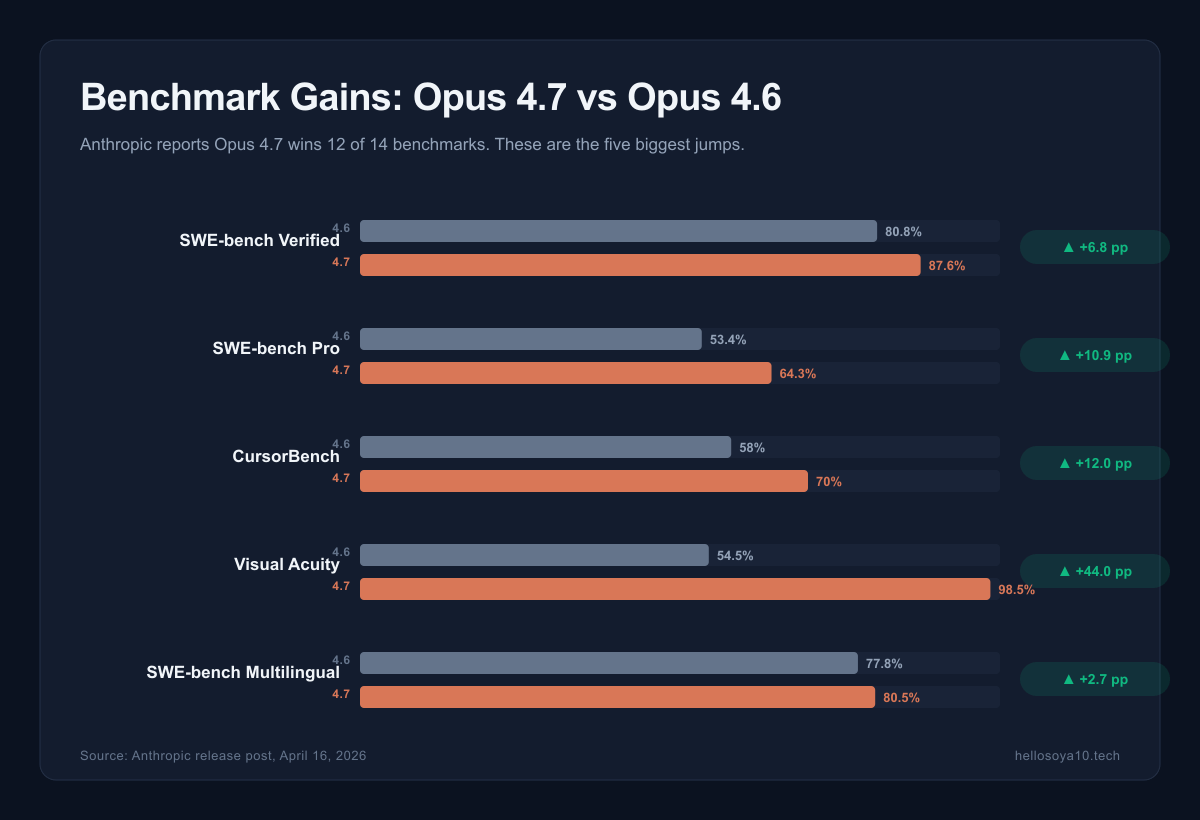
The Benchmarks That Moved the Most
Opus 4.7 won 12 of 14 reported benchmarks against Opus 4.6. The biggest jumps tell you what Anthropic actually focused on:
- MCP-Atlas: +14.6 percentage points — tool-use across Model Context Protocol servers
- CharXiv-R: +13.6 pp — reasoning over scientific charts and figures
- SWE-bench Pro: +10.9 pp — multi-file, multi-step coding tasks with ambiguity
- SWE-bench Verified: +6.8 pp to 87.6% — human-validated GitHub issues
- SWE-bench Multilingual: +2.7 pp to 80.5% — coding across non-English codebases
- CursorBench: +12 pp to 70% — the benchmark Cursor publishes for their editor agent
The pattern is obvious. Anthropic optimized for the use case that actually generates revenue: agentic coding at production quality, across real codebases, with real tools.
If you measure success by "did the patch land and pass CI without human intervention," Opus 4.7 is the first model that crosses 60% on the hard version of that test.
What It Looks Like in Production
Benchmarks are benchmarks. What enterprises are seeing is more interesting.
Box ran an A/B migration from Opus 4.6 to 4.7 on their production agentic workflows and published the numbers. The headline:
- 56% reduction in model calls per completed task
- 50% reduction in tool calls per completed task
- 24% faster end-to-end latency
- 30% fewer AI Units consumed (their internal billing unit)
Why does this happen? Because Opus 4.7 catches its own logical faults during planning, instead of diving into an execution that will need correction two turns later. Fewer wrong turns means fewer API calls means lower bills, even though the per-token price didn't move.
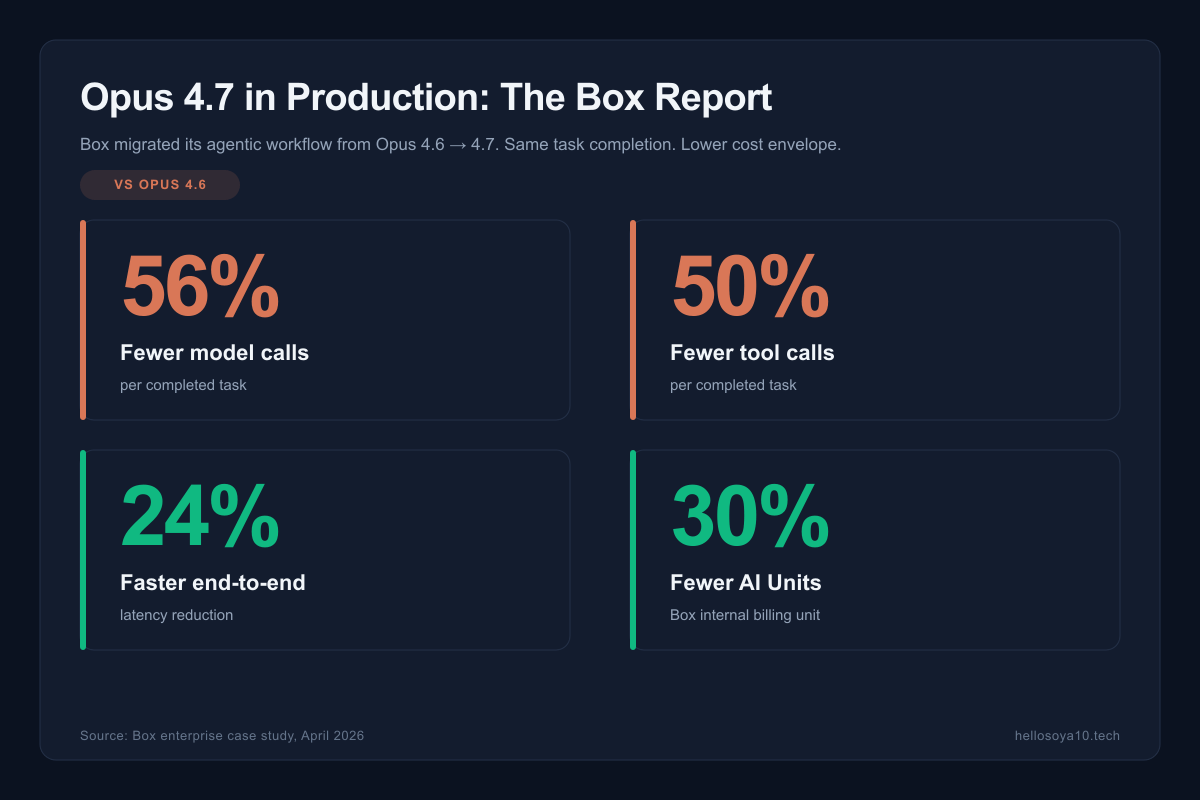
The other signal worth noting: Opus 4.7 solves 3× more production tasks than 4.6 at the same budget. That is a different kind of improvement than "scored higher on a benchmark." It is the number that matters when you are deciding whether a model is ready to run autonomously inside your workflow.
The Cyber Verification Program — What Safety Looks Like Now
One of the quiet launches alongside Opus 4.7 is the Cyber Verification Program, a new class of safeguards for requests involving cybersecurity activities that are almost always malicious with little to no legitimate defensive use case.
Practically, Opus 4.7 automatically detects and blocks requests that pattern-match to:
- Exploit development for specific CVEs on running targets
- Offensive tooling aimed at third-party systems
- Certain categories of credential-harvesting code
This is narrower than previous blanket refusals. Legitimate pentest work, CTF challenges, defensive reverse engineering, and academic security research still pass. What gets blocked is the explicit "build me a working exploit against X" class of request — the one Mythos handled too fluently for comfort.
Anthropic also reports gains on honesty benchmarks and resistance to malicious prompt injection compared to 4.6. The difference is incremental, but it's in the right direction.
Same Sticker Price, Different Bill
This is the part most reviews bury. Opus 4.7 is priced identically to 4.6:
- $5 per million input tokens
- $25 per million output tokens
But Anthropic also shipped a new tokenizer. On the same English text, the new tokenizer can map to 1.0× to 1.35× more tokens than the 4.6 tokenizer. Code and structured data trend toward the higher end of that range.
So the math:
- Rate card: unchanged
- Real tokens per identical prompt: up to 35% more
- Task budgets API: yes, use them
Net effect for most developers: if your workload shifts from 4.6 to 4.7 with no other changes, expect your bill to move anywhere from flat to +25%. The Box-style gains (56% fewer calls) more than offset this for agentic workflows. For simple one-shot chat? You might actually pay slightly more.
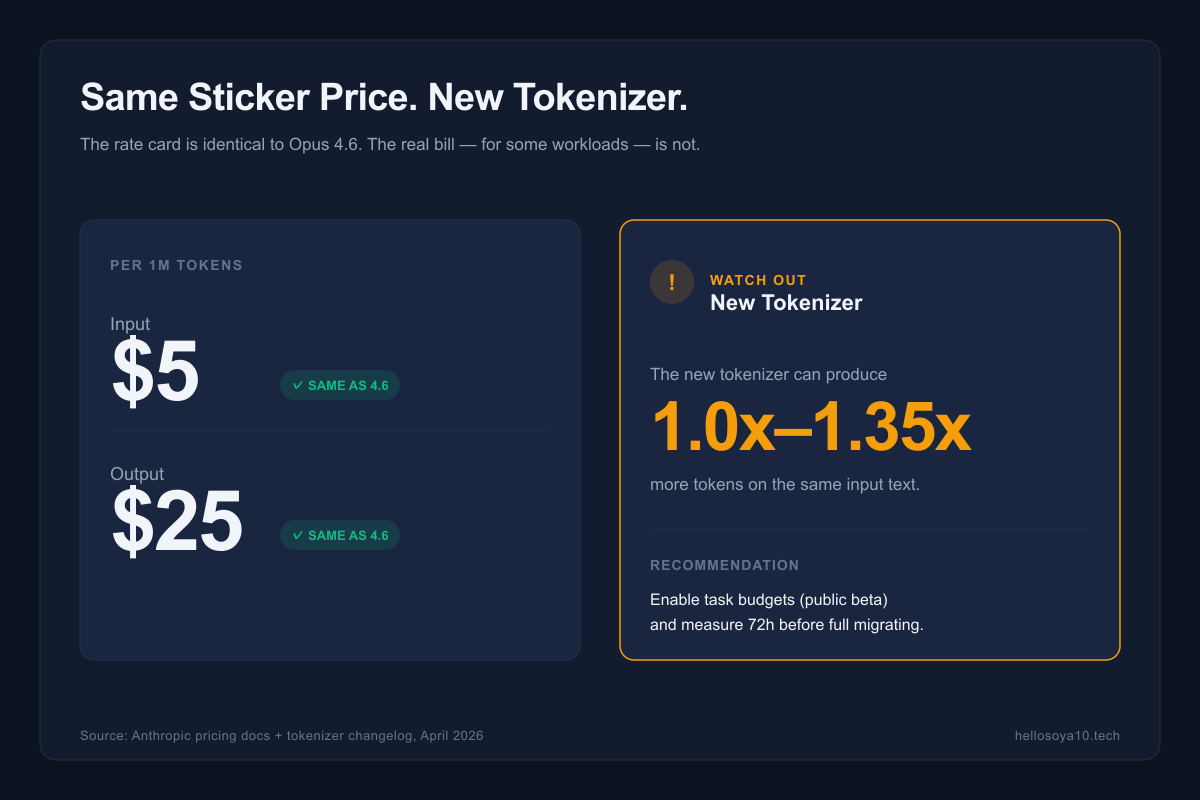
The safe pattern is to enable the new task budgets feature on the API the first week, measure your actual token spend on representative workloads, and then decide whether to rewrite any prompts. Do not migrate blindly and discover a 30% bill surprise at the end of the month.
Should You Upgrade From Opus 4.6?
Short version:
- Agentic coding workloads → Yes. The call-reduction alone pays for any token inflation, and the self-verification behavior means less human babysitting.
- Long-running agents (>30 min) → Yes, specifically for the context-handling improvements.
- Vision-heavy workflows → Yes. The resolution jump is a free capability upgrade.
- Simple chat assistants with short prompts → Test first. You might eat the tokenizer inflation without benefit.
- Pure reasoning/math → Likely yes, but Opus 4.7's gains are concentrated in coding and tools. For clean analytical work, the delta is smaller.
The one workflow where I'd hesitate is high-volume, short-prompt customer-facing assistants where response quality is already good enough. For that, Haiku-class models are probably a better optimization target anyway.
How to Access Claude Opus 4.7
Opus 4.7 is live today across:
- Claude.ai (web + apps) — the default model for Pro and Team users
- Claude API — model string
claude-opus-4-7 - AWS Bedrock — available in the Anthropic catalog
- Google Cloud Vertex AI — enterprise tier
- Microsoft Foundry — via the Anthropic integration
- Cursor, Windsurf, Cline, and other major coding agents — rolled out in their release channels
Task budgets are in public beta on the direct API — you'll want to opt in explicitly if you're running long agent jobs.
The Bottom Line
Opus 4.7 is not the model that sets the next frontier. Mythos already did that, and Anthropic is keeping Mythos locked up for now. What 4.7 does is ship the Mythos-era improvements in a form that is actually usable: same price, same SLAs, same safety envelope your security team already approved.
For builders, that is the more important release. A model you can deploy today beats a benchmark you can't access.
If you run any kind of coding agent in production, migrate this week. Enable task budgets, measure the first 72 hours of real usage, and let the reduced call counts tell you whether the upgrade paid for itself. For most agentic workloads, it will.
Building something with Claude Opus 4.7 and want a write-up? Get in touch — I write about what actually ships, not what gets announced.
コメントを残す