
A Chinese AI Lab Just Built a Self-Improving Model That Rivals Claude — for 17× Less

In January 2025, DeepSeek rattled the AI industry by shipping a reasoning model that matched Western frontier systems at a fraction of the cost. Fourteen months later, another Shanghai-based lab has done something arguably more interesting — and almost nobody outside the developer community noticed.
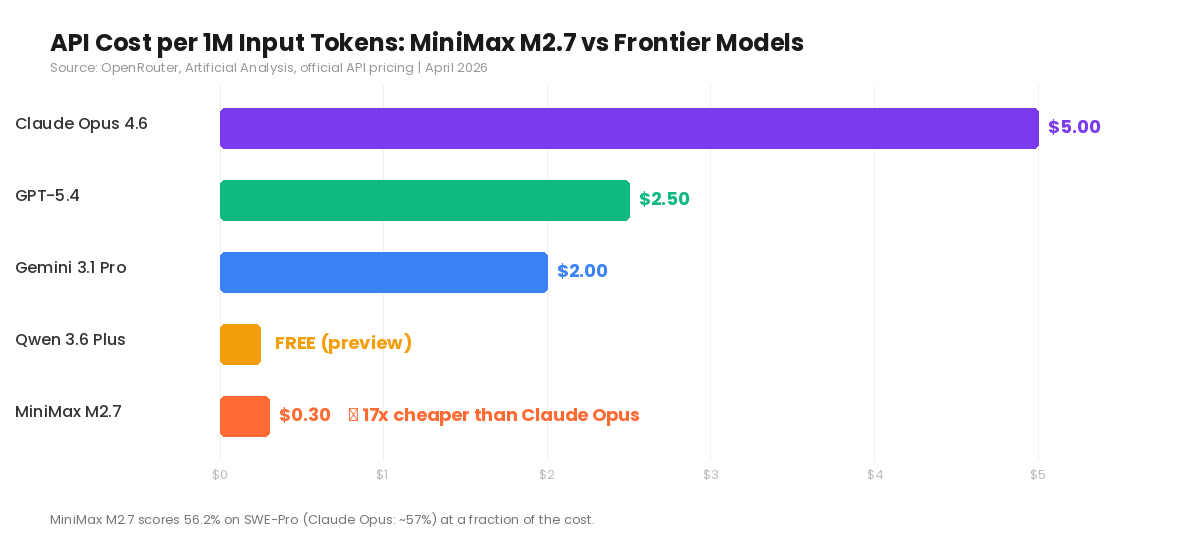
MiniMax M2.7 launched on March 18, 2026, with a claim that sounds like marketing hyperbole until you check the benchmarks: frontier-tier coding performance at $0.30 per million input tokens. For context, Claude Opus 4.6 charges $5.00 for the same volume. That’s a 17× price difference.
But the price isn’t even the most unusual part. The model was trained using a “self-evolving” loop — over 100 autonomous optimization rounds where M2.7 effectively improved its own training process. If that architecture holds up in production, it changes the economics of model development itself.
The Numbers
M2.7 runs on a Sparse Mixture-of-Experts architecture with approximately 230 billion total parameters, of which only 10 billion activate per token inference. That architectural choice is what keeps the cost floor so low — you’re not paying to run the full parameter set on every query.
On SWE-Pro, the most demanding software engineering benchmark currently in use, M2.7 scores 56.22%. Claude Opus 4.6 sits at roughly 57%. That gap is measurable but narrow enough that for most production coding tasks, the output quality is functionally equivalent.
On Terminal-Bench 2.0, M2.7 hits 57.0%. On the Artificial Analysis Intelligence Index, it ranks first out of 136 evaluated models with a score of 50, where the field average is 19.
The catch, as with many Chinese models, is speed. Independent benchmarks measure M2.7 at roughly 45 tokens per second on the standard endpoint — slower than the category median of around 95 tokens per second. MiniMax claims a “highspeed” variant running at 100 tokens per second, but third-party verification of that number is still pending.
What “Self-Evolving” Actually Means
Most AI models improve through one mechanism: humans label data, engineers retrain, performance goes up. M2.7 adds a second loop. The model runs autonomous optimization rounds where it evaluates its own outputs, identifies failure modes, and feeds corrections back into training — without human intervention at each step.
MiniMax ran over 100 of these self-improvement cycles during M2.7’s development. The practical result is that M2.7 shipped just weeks after its predecessor M2.5, with substantially better performance on engineering benchmarks. That iteration speed is what makes the architecture notable; it compresses what typically takes months of human-supervised training into weeks.
Whether this approach scales to frontier-plus performance or plateaus at current levels is the open question. But the trajectory — M2 in October 2025, M2.5 in February 2026, M2.7 in March 2026, each improving significantly — suggests the loop is working.
Where It Fits in a Real Workflow
For anyone running Claude Code, Cursor, or similar AI coding tools, M2.7 represents a practical option for the high-volume, lower-stakes portion of your workflow. Code reviews, boilerplate generation, test writing, documentation — tasks where 90% of Claude’s quality at 7% of the cost is a rational trade.
The 200K token context window is production-grade for most codebases. Automatic caching (at $0.06 per million tokens for cache reads) further reduces costs on repetitive workflows. Native function calling and JSON mode support means it slots into existing agent frameworks with minimal integration overhead.
Where I wouldn’t use it: safety-critical applications, anything requiring strong factual grounding without external verification, or latency-sensitive interactive use where the slower inference speed becomes a blocker.
What This Signals
MiniMax listed on the Hong Kong Stock Exchange in January 2026 — the same exchange that saw Zhipu AI’s IPO shortly after. Chinese AI companies are entering public markets while shipping models that compete directly with Anthropic and OpenAI on technical benchmarks, at dramatically lower price points.
The competitive pressure here is directional. Every time a Chinese lab demonstrates near-parity performance at 10–20× lower cost, it forces Western providers to either justify the premium through quality differentiation, safety guarantees, and ecosystem lock-in — or cut prices. Both outcomes benefit developers.
M2.7 isn’t going to replace Claude or GPT for everything. But for the growing category of AI-assisted development tasks where “good enough at dramatically lower cost” is the right engineering decision, it’s now the strongest option on the market.
Oliver Wood writes about AI tools, behavioral economics, and the intersection of technology with content creation. Follow on Medium @oliver_wood for weekly articles.

コメント