
- Alibaba Is Giving Away a 1-Million-Token AI Model for Free — Here’s What It Can Actually Do
- What 1 Million Tokens Looks Like in Practice
- Benchmark Reality Check
- The “Always-On” Reasoning Difference
- How to Access It Right Now
- What It Means for Your AI Stack
- Related
- Turn this idea into a working AI workflow.
Alibaba Is Giving Away a 1-Million-Token AI Model for Free — Here’s What It Can Actually Do

On March 31, 2026, Alibaba’s Qwen team dropped a model on OpenRouter without a press release, without a launch event, and without charging a single dollar. Qwen 3.6 Plus Preview appeared with a 1-million-token context window, always-on chain-of-thought reasoning, and benchmark scores that place it within striking distance of Claude Opus 4.6.
That last point is worth pausing on. A free model is competing with a $5/$25-per-million-token system on software engineering benchmarks — and winning on some of them.
Here’s what the numbers actually say, where it’s already better than what you’re paying for, and where the catch is.
What 1 Million Tokens Looks Like in Practice
One million tokens is approximately 750,000 words or 1,500 pages of dense technical documentation. In practical terms, this means you can feed an entire mid-sized codebase into a single prompt without chunking, splitting, or retrieval-augmented workarounds. An entire book-length legal contract. Hours of transcribed meeting notes. A full project repository plus its documentation plus its test suite — all in one context window.
For comparison, Claude Opus 4.6 also offers 1M token context (no surcharge), and GPT-5.4 sits at 1.05M. Qwen 3.6 Plus matches the frontier on context length while adding a higher output ceiling: 65,536 tokens per response, the largest among the three.
The context window alone isn’t the differentiator. What makes it interesting is the combination: 1M context, always-on reasoning, native function calling, and zero cost during the preview window.
Benchmark Reality Check
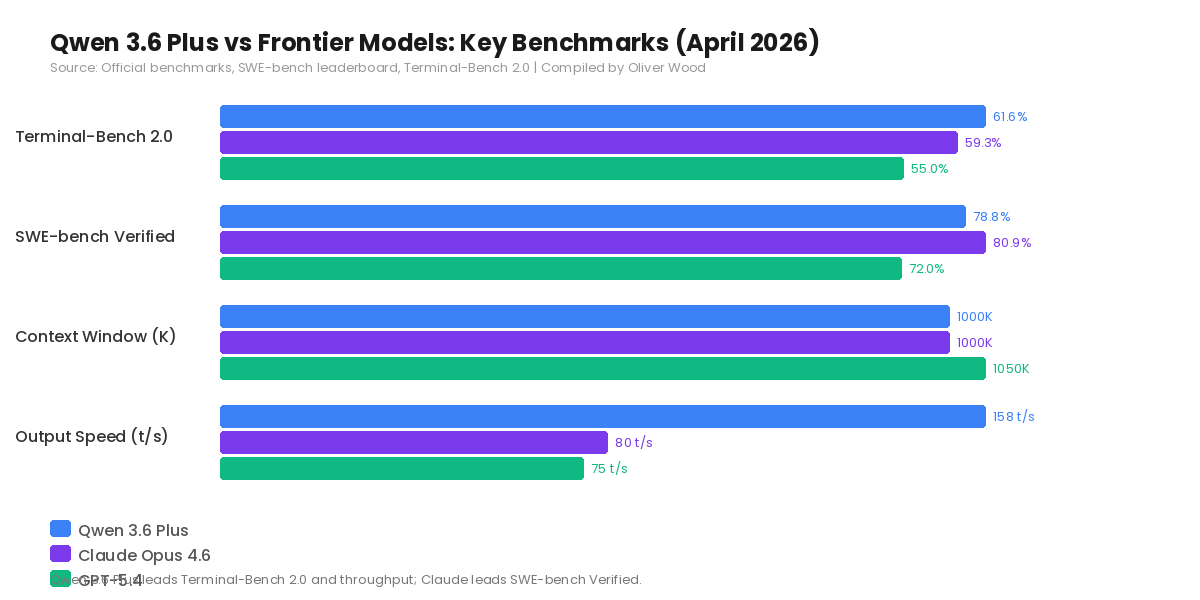
Terminal-Bench 2.0, which measures autonomous terminal-based coding workflows, is where Qwen 3.6 Plus leads the field. It scores 61.6% against Claude Opus 4.6’s 59.3%. For developers building agent systems that interact with command-line environments — debugging, deployment automation, infrastructure scripting — this is the most relevant benchmark.
On SWE-bench Verified, Claude Opus maintains a narrow lead at 80.9% versus Qwen’s 78.8%. This benchmark tests real-world GitHub issue resolution, so the gap matters for production-grade code generation.
Throughput is where Qwen pulls decisively ahead: 158 tokens per second median, roughly double Claude Opus 4.6’s approximately 80 tokens per second. In interactive coding workflows where latency compounds across dozens of calls per session, that speed advantage translates directly into developer time saved.
The trade-off sits in safety and factual accuracy benchmarks, where Claude and GPT-5.4 maintain clear leads. For enterprise applications with compliance requirements, this gap is significant. For individual developers and small teams, it’s less likely to be a blocking factor.
The “Always-On” Reasoning Difference
Qwen 3.5 had a persistent complaint: it overthought simple tasks. Ask it to format a JSON response, and it would spend tokens reasoning about data structures before producing a three-line output.
Qwen 3.6 Plus keeps chain-of-thought reasoning permanently active but recalibrates how much thinking is appropriate for each request. The model reaches answers in fewer tokens on routine tasks while maintaining deep reasoning for complex multi-step problems. A new preserve_thinking parameter allows agent frameworks to retain the model’s internal reasoning across conversation turns — meaning it doesn’t lose its analytical thread during long agentic sessions.
This architectural choice has a concrete benefit for agent builders: you don’t need to manage a thinking-mode toggle per request. Every call gets appropriate reasoning depth automatically.
How to Access It Right Now
The model is live on OpenRouter using the model string qwen/qwen3.6-plus-preview:free. No API key payment required during the preview period. It also runs through Alibaba’s DashScope API and Model Studio platform.
One important caveat: during the preview, Alibaba collects prompt and completion data for model improvement. Don’t send confidential client data, proprietary code, or sensitive business information through the free endpoint. For development, benchmarking, and non-sensitive workflows, the access is genuinely useful and genuinely free.
The preview will eventually transition to a paid model. Historical Qwen pricing has been aggressively competitive — Qwen 3.5 Plus ran at roughly $0.30–0.80 per million tokens depending on the provider — so expect the general availability pricing to land well below Claude and GPT tiers.
What It Means for Your AI Stack
If you’re currently paying for Claude API calls across every task in your workflow, Qwen 3.6 Plus creates an opportunity to tier your spending. Route the high-stakes, safety-sensitive, factual-accuracy-critical work through Claude or GPT. Route the volume coding, long-context analysis, and agent loops through Qwen at zero cost during preview (and dramatically lower cost after GA).
This isn’t an either/or decision. The most rational approach in April 2026 is a multi-model stack where you match each task to the model that optimizes the quality-to-cost ratio for that specific workload.
Alibaba didn’t announce this model with fanfare. They published benchmark numbers via a researcher’s X post and made it available for free. That quiet confidence — shipping the product and letting developers decide — is increasingly characteristic of how the strongest Chinese AI labs operate.
Oliver Wood writes about AI tools, behavioral economics, and the intersection of technology with content creation. Follow on Medium @oliver_wood for weekly articles.

コメント