After Claude Opus 4.7 arrived, I started seeing a specific anxiety: did the new tokenizer make Japanese more expensive?
I had the same question.
I use Claude Max 20x, and I have been running Claude Code in parallel more often. Even with the higher plan, the weekly limit started feeling more real. Not because I was asking longer casual questions, but because agentic coding sessions can quietly turn into huge context machines.
After digging into the official notes and third-party tokenizer checks, my conclusion is:
In the available samples, Japanese prose does not look like the main culprit.
The bigger issue is Claude Code context.
When you ask in Japanese, the model may still receive English tool schemas, JSON, source code, diffs, terminal logs, stack traces, package files, documentation, and long conversation history. Those are exactly the content types that appear more likely to grow under the Claude 4.7 tokenizer.
The visible language of your prompt is not the whole workload the model sees.
So the useful framing is not:
Japanese became expensive.
It is closer to:
My read is that Claude Code workflows became easier to overfeed, especially when multiple agents run in parallel.
That distinction matters if you are using Max 20x and trying to avoid burning through the week too early.
What Anthropic Officially Says
Anthropic's Claude Opus 4.7 announcement positions the model as a stronger system for coding, agentic work, computer use, long-running tasks, and document-heavy reasoning.
Anthropic also says Opus 4.7 keeps the same API price as Opus 4.6, while improving efficiency on long-running work by reducing unnecessary steps.
The tokenizer detail appears in Anthropic's model migration guide. The important point is that Claude Opus 4.7 uses an updated tokenizer, and existing applications may see token counts increase by roughly 1.0x to 1.35x.
That is the official caution.
But the official note does not say "Japanese became unusually expensive." It says the tokenizer changed, and applications may see increased token counts.
Anthropic's Max plan usage page is also relevant. Max usage is affected by message length, attachments, conversation length, model choice, and the features being used.
That means two Max 20x users can have very different experiences:
| User pattern | Likely feeling |
|---|---|
| Short chats, clean new conversations | Plenty of room |
| Long Claude Code sessions with files and logs | Limit feels much closer |
| Parallel Claude Code agents | Weekly cap becomes psychologically scary |
If you are using the API, Anthropic's Token counting documentation is worth reading too. The counting endpoint can estimate input tokens before sending a request, and it can include not just text, but system prompts, tools, images, PDFs, and other structured inputs.
For Max users, this should not be read as API token billing. Max limits are product usage limits across Claude surfaces, while token counts are still useful for understanding why long, tool-heavy sessions can consume usage faster.
That is the key lesson: token usage is not only the visible sentence you typed.
The hidden context matters.
The Language Tests Do Not Point to Japanese as the Main Problem
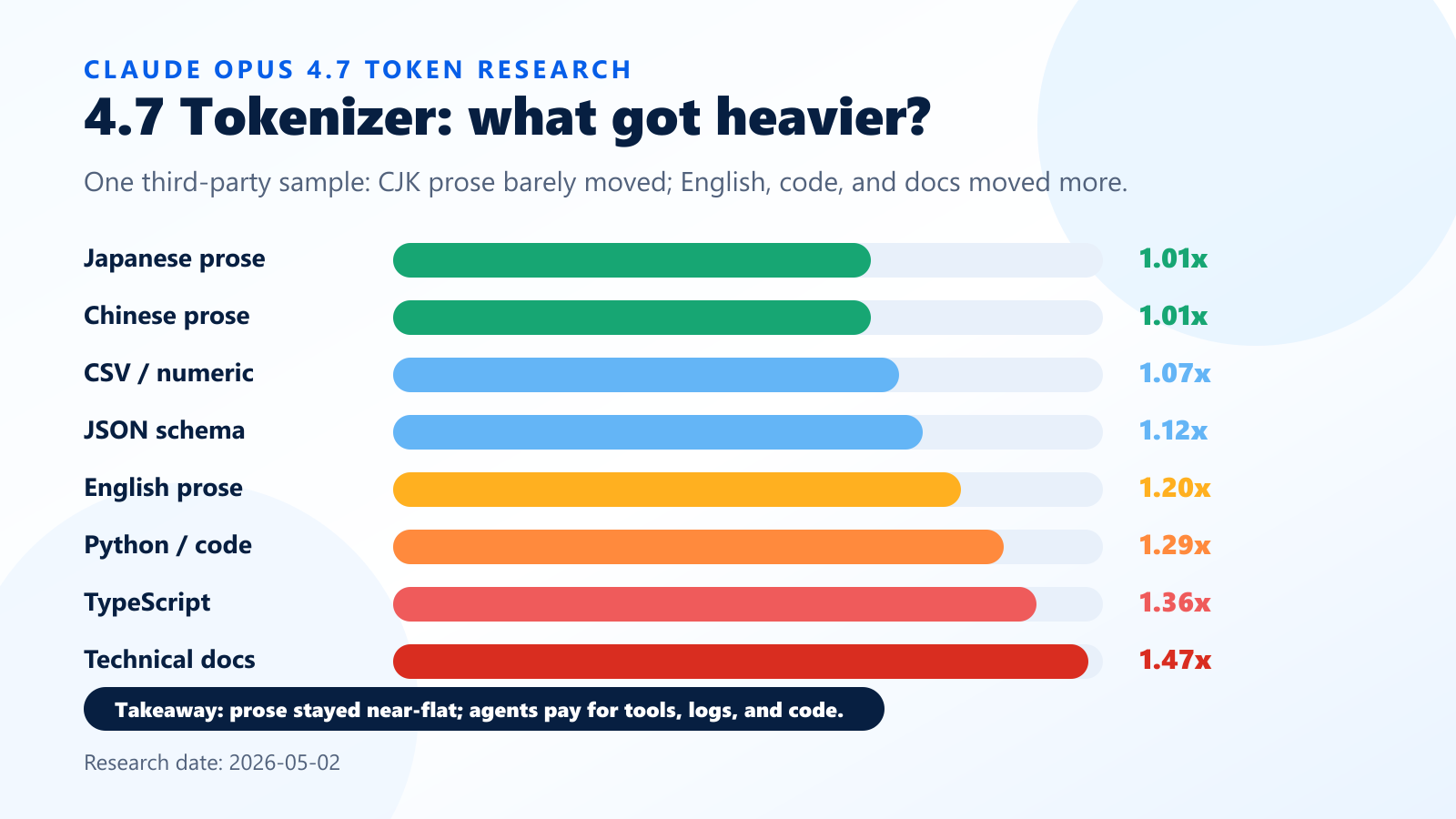
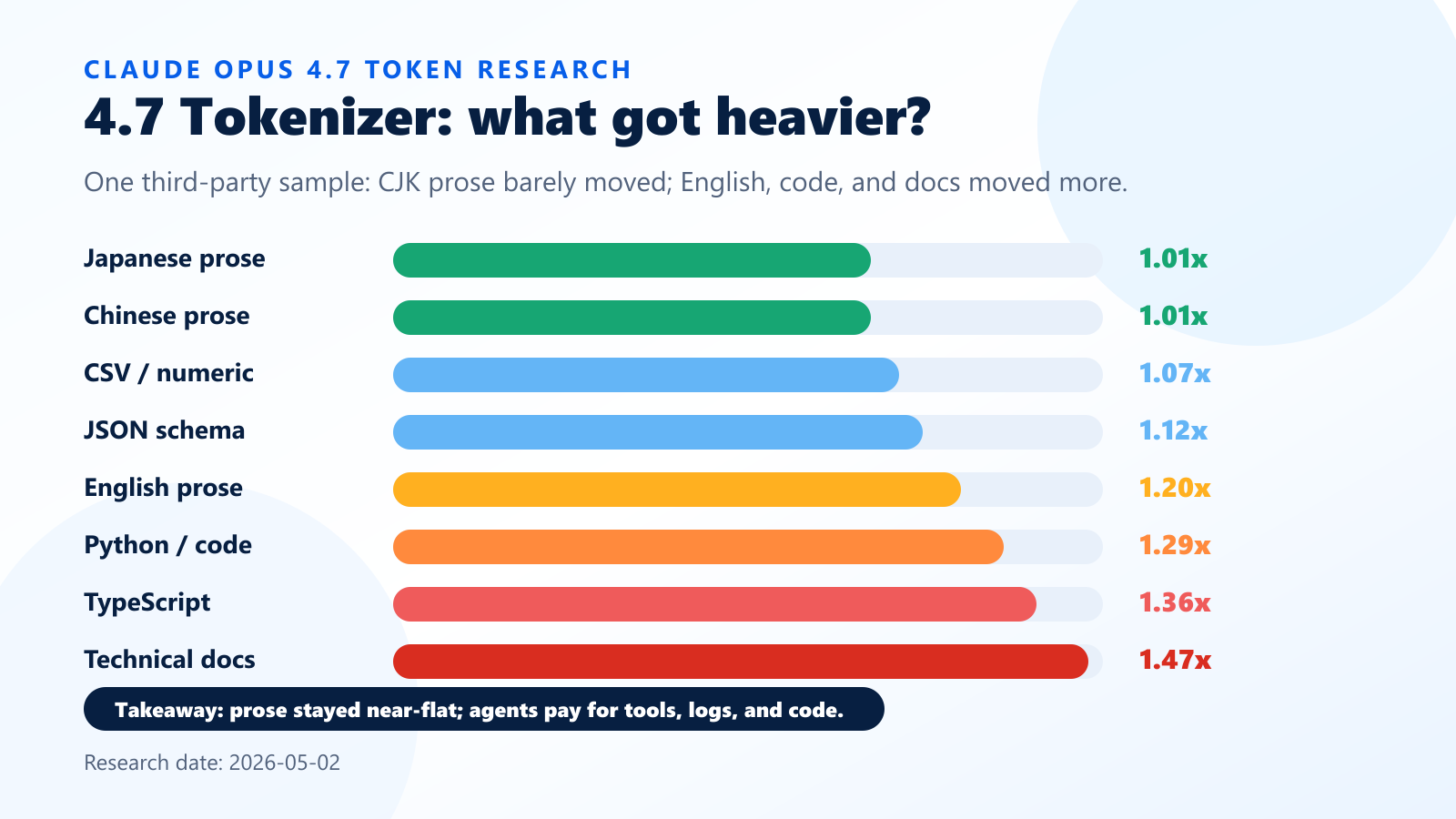
The content-type table below relies mainly on ClaudeCodeCamp's direct token-counting test using Anthropic's count_tokens endpoint. OpenRouter's Claude Opus 4.7 tokenizer analysis is a separate third-party analysis based on real usage logs and prompt-size buckets, not this exact language-by-language table.
These numbers are not official guarantees. They depend on the sample text and testing method, and the official 1.0x to 1.35x guidance should not be treated as a universal hard ceiling for every possible content mix.
Still, the direction is useful:
| Content type | Approximate 4.6 to 4.7 token ratio |
|---|---|
| Japanese prose | 1.01x |
| Chinese prose | 1.01x |
| CSV / numeric data | 1.07x |
| JSON schema | 1.12x |
| English prose | 1.20x |
| Python / code | 1.29x |
| TypeScript | 1.36x |
| Technical docs | 1.47x |
Read this carefully.
The evidence does not support the simple claim that "Japanese got crushed by Claude 4.7." In the sample above, Japanese prose barely moved.
But code, TypeScript, English prose, and technical documentation moved more.
That explains the mismatch between "Japanese looks fine in a language test" and "my Claude Code usage feels heavier."
Claude Code is not a pure Japanese prose workload.
It is a mixed workload made of:
- your Japanese instruction
- repository files
- English dependency names
- TypeScript or Python code
- JSON tool calls
- terminal output
- stack traces
- diffs
- previous conversation history
- documentation snippets
So even if your prompt is Japanese, the heavier part may be everything around the prompt.
Why Max 20x Can Still Feel Tight

Claude Max 20x is a powerful plan.
But "20x" does not mean "run unlimited parallel agents without thinking."
The pressure comes from several layers stacking together:
- the tokenizer can make the same technical context larger
- coding sessions naturally involve more files and tool output
- long conversations carry more history
- Claude Code can repeatedly read, edit, test, and retry
- high-reasoning runs may produce more thinking and output
- multiple sessions each maintain their own context
- weekly usage is not shown as a simple token counter
That last point is underrated.
The anxiety is not only about cost. It is about uncertainty.
When you run three or four Claude Code tasks in parallel, each task looks small from the outside:
Fix this error.
Review this file.
Run the tests again.
Check the implementation.
But internally, each loop may carry tool definitions, files, logs, diffs, and history. The task feels small to the user, while the model sees a much bigger context.
That is why Max 20x can start feeling fragile if you treat Claude Code like an always-on worker pool.
The problem is not that Max 20x is weak.
The problem is that parallel agentic coding can consume context faster than intuition expects.
Why I Am Moving to a Codex-First Workflow

My practical conclusion is simple:
Use Codex as the main workbench. Use Claude Opus 4.7 surgically.
Claude Opus 4.7 is still valuable. I would still use it for hard architecture, ambiguous debugging, deep review, and decisions where a wrong answer is expensive.
But I do not want Opus 4.7 doing every routine task.
For my workflow, this split makes more sense:
| Work type | Better default |
|---|---|
| File edits, repo changes, article packaging | Codex |
| WordPress formatting, local scripts, repeatable operations | Codex |
| Research structuring and draft assembly | Codex |
| Hard architecture decisions | Claude Opus 4.7 |
| Deep review of risky changes | Claude Opus 4.7 |
| Short summaries or low-risk checks | Lighter model or new chat |
This is not about which model is "better."
It is about where scarce high-end reasoning quota creates the most value.
If Claude saves a major design mistake, it is worth the quota.
If Claude is only formatting a post, checking a typo, or repeating a deterministic local operation, that is a poor use of Max capacity.
Rules I Would Use for Max 20x
If you are using Claude Max 20x with Claude Code, I would treat quota like a weekly engineering budget.
1. Limit Opus 4.7 parallelism
Unless a deadline truly requires it, I would keep Opus 4.7 parallel coding sessions to one or two.
Parallel agents feel productive, but they also multiply hidden context.
2. Give each Claude session one clear win condition
Do not make one long Claude thread handle everything.
Use goals like:
- identify the root cause of this bug
- review this PR for risky regressions
- compare these two architecture options
- explain why this test suite is failing
The narrower the goal, the less the context balloons.
3. Do not paste huge logs raw
Large logs are quota traps.
Summarize first. Keep the exact error, the relevant stack frame, and the command that produced it.
Send the full log only when the full log is genuinely needed.
4. Stop using Opus as a confirmation button
"Is this okay?" is often not worth Opus 4.7.
Use Codex, a lighter model, a checklist, or local tests for routine confirmation.
Save Opus for moments where the reasoning actually changes the outcome.
5. Start a new chat when the old context stops paying rent
Long context is not free.
If the session has drifted, start fresh and bring only the distilled facts forward.
This matters even more when you are using agents, because old context can stay attached to work that no longer needs it.
6. Ask the quota question before using Claude
Before sending a task to Opus 4.7, ask:
Will this save enough human time or reduce enough risk to justify burning scarce Max quota?
If the answer is no, route it to Codex or a cheaper workflow.
How to Test Your Own Workflow
If you want to know whether Claude 4.7 is hurting your own usage pattern, do not rely only on vibes.
Track three categories for one week:
| Category | What to observe |
|---|---|
| Normal Japanese chat | Does plain Japanese feel meaningfully different? |
| Small Claude Code fixes | How much file and log context gets pulled in? |
| Long autonomous Claude Code runs | When does history and tool output start to balloon? |
If you use the API, test representative prompts with Anthropic's token counting endpoint.
If you use Claude.ai or Claude Code through Max, you may not see every internal number. But you can still track:
- how many parallel sessions you ran
- how long each session lasted
- whether you attached files
- whether you pasted raw logs
- whether you kept old conversations alive
- when weekly limit anxiety started
That will usually tell you whether the pressure is coming from Japanese text itself or from agent context.
My bet is that, for many power users, it is the second one.
My Take
I do not think the right headline is:
Claude 4.7 made Japanese expensive.
The better headline is:
Claude 4.7 made it more important to manage agent context.
Japanese prose does not appear to be the main problem in the available tokenizer comparisons. But Claude Code is not Japanese prose. It is a dense mixture of code, English documentation, logs, JSON, diffs, tools, and accumulated history.
That is why Max 20x can feel tighter after Opus 4.7, especially if you run parallel coding agents.
For me, the practical answer is Codex-first.
Codex handles implementation, local files, WordPress packaging, scripts, and routine iteration.
Claude Opus 4.7 stays reserved for the highest-leverage reasoning:
- hard bugs
- architecture judgment
- deep review
- ambiguous decisions
- tasks where a better answer saves real human time
The lesson is not to avoid Claude.
The lesson is to stop treating the strongest model like an always-on background worker.
Use it where the reasoning pays for the quota.


コメント