
結論を先に書く。ChatGPT 5.5 Instant は便利だが、速さは思考の代替ではない。OpenAI が 2026-05-05 に公開した 5.5 Instant は、確かに速くて使いやすい。だが「AI が答えたから正しい」という前提で受け取ると、検証を怠るリスクが上がる。本記事は機能紹介ではなく、Instant をどう疑い、どう使い分けるかを批判的に整理する。
主要キーワード: ChatGPT 5.5 Instant、GPT-5.5 Instant、Instant Thinking 違い、クリティカルシンキング、AI時代 人間の役割。
ChatGPT 5.5 Instantとは何か
公開されている事実から整理する。OpenAI 公式のリリース文書によると、5.5 Instant は GPT-5.5 シリーズの 2 ティア(Instant / Thinking)のうち、高速・汎用の default モデルとして位置づけられる(OpenAI Introducing GPT-5.5)。複雑なタスクは自動で Thinking に切り替わる仕組みが導入されている(OpenAI Help Center)。
API 価格は input $5 / output $30 per 1M tokens(OpenAI API pricing)。ChatGPT 上の利用枠は、無料が 5 時間あたり 10 メッセージ、Plus / Go が 3 時間あたり 160 メッセージ、Pro 以上は実質無制限(ChatGPT pricing)。
向いている用途は、文章作成、要約、SNS 投稿、アイデア出し、軽い調査、ブログ記事の構成案。逆に、複雑な多段推論、高精度な検証、コード設計など腰を据える仕事は、Thinking の領分とされる。
速度は思考を助けるのか
ここから批判的に読む。速い回答が思考を助ける、というのは半分しか正しくない。
OpenAI 公式は、5.5 Instant について「個別主張の正確性が 23% 向上、応答内の factual error が 3% 減少」と発表している(OpenAI Deployment Safety)。技術プレスはさらに「前世代比 60% の幻覚減」と書いている(StartupFortune)。数字だけ見れば、速くて正確になった。
ところが第三者ベンチマークでは話が変わる。AA-Omniscience の独立評価では、GPT-5.5 系の幻覚率は依然として 86% に達し、OpenAI のクレームと数字の上で衝突している(The Decoder)。評価軸の違いで説明できる範囲はあるが、「23% 改善」と「86% は誤る」は同じ世界の話とは言いにくい。
これは Instant に限った話ではないが、速さは検証の省略を誘発する。即座に出てきた答えは、「もう確認したつもり」になりやすい。2026 年の CHI 学会で報告された研究では、AI を後から相談したユーザーのほうが、批判的思考タスクで成績が良かった(Science News)。最初から AI に問えばいい、という直感は、思考の質という観点では裏目に出る場面がある。
正確性が上がったAIをどこまで信頼するか
ハルシネーションが減ってもゼロにはならない。これは Instant の問題ではなく、現行 LLM の構造的な限界だ。減少率が大きくても、残存リスクは「100% 信頼してよい」を意味しない。
検証が要らない情報と、検証が要る情報は分けたほうがいい。
検証が要らないか、要っても軽い情報の例: SNS 投稿のドラフト、ブログ記事の構成案、メールの言い換え、要約のたたき台、アイデア出しの壁打ち。これらは事実認識の精度よりも形が大事で、誤情報が出ても影響が小さい。
検証が要る情報: 統計、固有名詞、引用元、契約条項、医療・法律・金融に関わる判断、研究や論文のレビュー、コード設計の根拠。Instant の出力をそのまま一次判断にしないこと。Thinking に投げ直すか、公式情報を別ルートで確認するのが基本だ。
これも公式の注意として明記されている。OpenAI のデプロイメント安全文書は、「準備度評価とドメイン固有テストを行ったが、利用者側で chain-of-thought を含むモニタリング体制が必要」と書いている(OpenAI Deployment Safety)。OpenAI 自身、すべてを丸投げできるとは言っていない。
InstantとThinkingの使い分け

実用的な使い分けの目安を表にまとめる。
| 用途 | Instant 向き | Thinking 向き | 理由 |
|---|---|---|---|
| SNS投稿 | ◎ | — | 速さと量が重要、誤りの被害が小さい |
| 営業DM | ○(初稿) | △(戦略) | 初稿は Instant、戦略設計は Thinking |
| note記事構成 | ○ | △ | 構成作成は Instant で十分、検証は別 |
| 日常調査 | ○ | △ | 軽い lookup は Instant、深掘りは Thinking |
| コード設計 | △ | ◎ | 複雑な依存・トレードオフは Thinking |
| 論文レビュー | × | ◎ | 精密な検証が必要 |
| 医療・法律・金融 | × | ◎ + 専門家確認 | 誤情報のリスクが高すぎる |
| 重要意思決定 | × | ◎ + 人間の最終判断 | スコアの問題ではなく責任の問題 |
ルール・オブ・サム: 下書きは Instant、検証は Thinking、決定は人間。Instant でドラフトを取る → Thinking でロジックを詰める → 人間が文脈と責任を引き受ける、という三段構えにすると、速さも深さも両取りできる。
速度と思考の深さは別軸である
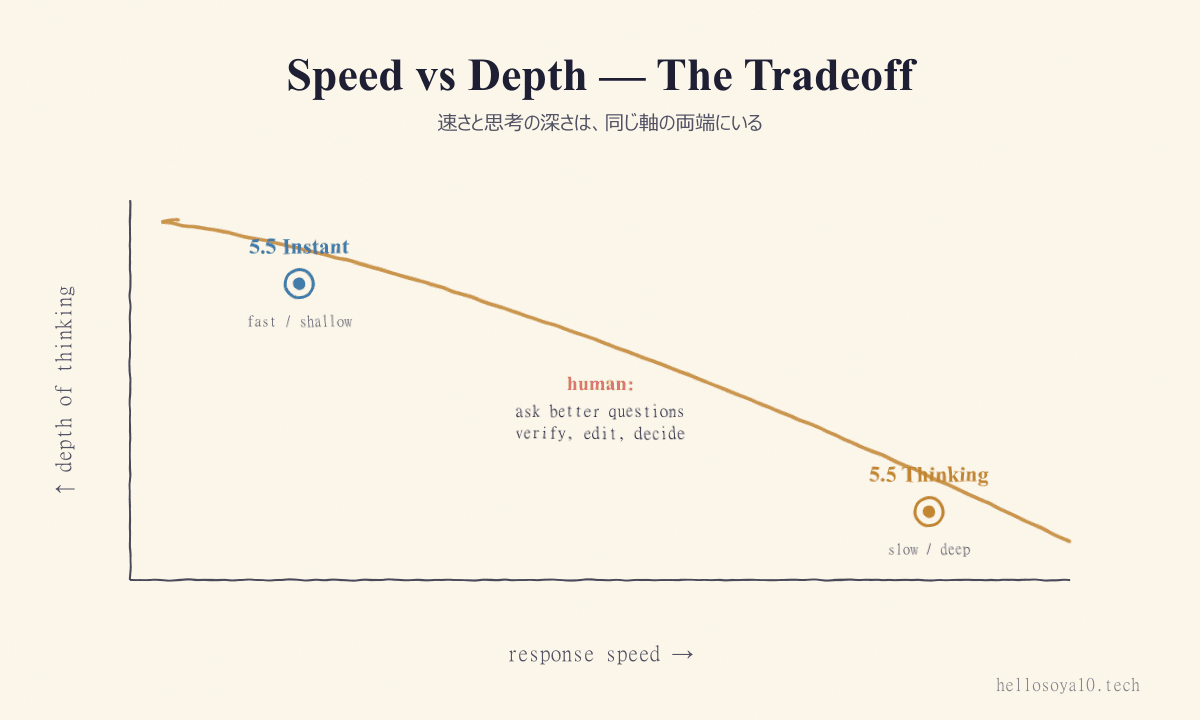
5.5 Instant の登場で議論されているのは、「速いほうが偉い」のか「深いほうが偉い」のか、という二項対立になりがちだ。が、実務はそうなっていない。
速度と思考の深さは、同じトレードオフ曲線の両端にあって、用途によってどちらが要るかが変わる。Instant は曲線の左上(速くて浅い)、Thinking は右下(遅くて深い)。重要なのは、自分の作業がどちらを要求しているかを判断する力で、これは AI の側ではなく人間の側に残る。
Codex 系 GPT-5.5 を使うなら、Codex GPT-5.5 実用ガイドで具体的なプロンプト設計を補ってほしい。GPT-5.5 全般のプロンプト設計はGPT-5.5 プロンプトガイドが参考になる。
AI時代に人間に残る価値
5.5 Instant が速く正確になっても、人間の仕事はゼロにはならない。むしろ仕事の中身が「作業」から「判断」にシフトする。残る価値は 5 つに整理できる。
第一に、問いを立てる力。AI に何を訊くかを決めるのは、最後まで人間の仕事だ。良い問いは良い答えを引き出す。雑な問いは、雑な答えを高速で量産する。
第二に、情報を疑う力。AI 出力には自信のある誤情報が混じる。これを「もっともらしいが本当か」と疑える人と、出てきた答えをそのまま使う人の差は、今後広がる。
第三に、文脈を読む力。AI は一般的な答えを出すのは得意だが、自分のチーム、業界、顧客の固有事情までは知らない。文脈を当てはめて翻訳するのは人間の役割。
第四に、最終判断する力。AI は責任を取らない。判断には責任が伴うので、判断は人間の仕事として残る。これは技術問題ではなく、社会的な合意の問題だ。
第五に、自分の言葉に編集する力。Instant の文体は便利だが、量産すると「同じ顔」になる。差別化は文体・体験・観点でしか起きない。AI を使う人と使わない人の差以上に、AI の出力を自分の言葉に編集できる人とできない人の差が、今後の競争軸になる。
関連: AI 全般の使い方を整える
ChatGPT 5.5 Instant 単体で完結する仕事は少ない。実務では、画像・動画・コードなど別領域の AI と組み合わせるシーンが増えている。低予算で AI 環境を整えたい人は、20 ドル AI スタックで月次コストを抑える組み合わせ例を確認できる。Claude や Cursor との比較を踏まえたい場合は、Opus 4.7 レビュー、Claude Code vs Cursor 2026が参考になる。AI ブログ運用の自動化シナリオはAI ブログ自動化ガイドにまとめてある。
FAQ
Q. ChatGPT 5.5 InstantとThinkingは何が違うのか?
Instant は高速・汎用の default モデルで、SNS、要約、構成、軽い調査が得意。Thinking は推論を重ねる重量級モデルで、コード設計、論文レビュー、複雑な検証が必要なときに使う。Instant は複雑なタスクで自動的に Thinking へ切り替わる仕組みも入っている(OpenAI Help)。
Q. ChatGPT 5.5 Instantは無料で使えるのか?
無料枠あり。無料アカウントは 5 時間あたり 10 メッセージ、Plus / Go は 3 時間あたり 160 メッセージ、Pro / Business / Enterprise は実質無制限(ChatGPT pricing)。重い使い方をするなら有料化が現実的だ。
Q. ハルシネーションは本当に減ったのか?
OpenAI 公式は個別主張の正確性が 23% 改善、factual error が 3% 減少と発表している。一方で第三者ベンチマーク(AA-Omniscience)では幻覚率が 86% という結果も出ており、評価軸が違う。減ったが、ゼロになったわけではない、というのが現時点の安全な理解だ。
Q. 医療・法律・金融の判断にChatGPT 5.5 Instantを使ってよいか?
一次判断には使うべきではない。Instant は速さ重視のモデルで、検証が要る領域には設計されていない。たたき台やリサーチ補助として使い、最終判断は専門家か Thinking 経由の検証ワークフローに任せるのが安全。これは Instant の性能の問題ではなく、責任の問題だ。
Q. Instantを使えば仕事は速くなるのか?
ドラフト作業は確実に速くなる。一方で、検証や判断にかかる時間が減るわけではない。むしろ「速く出てくるから検証を省く」という罠に落ちると、後工程で品質問題が出る。速度の改善は前工程に効き、後工程の責任は人間に残る、と理解すると失敗しにくい。
まとめ
ChatGPT 5.5 Instant は、速く答えを出すための道具だ。便利で、強力で、ドラフト工程を圧縮する。だが AI 時代に本当に重要なのは、速く答えることではない。良い問いを立て、答えを検証し、自分の文脈に合わせて編集する力である。
この記事の中心メッセージは 1 行に収まる。道具の性能ではなく、使い手の問いの質が成果を決める。Instant は思考の代替ではなく、思考の起点として使う。それが、AI を使う人と使わない人ではなく、AI を使いこなす人と使われる人の境界線になる。
——
🌱 メルマガ登録: 個人メディアで AI を実務に組み込む試行錯誤を、週 1 回お届けします。ニュースレター登録はこちら
📬 スポンサー / お仕事のご相談: AI 関連プロダクトのレビュー記事、メディア制作、コンサルティングなど、お問い合わせフォームからご連絡ください。
📚 次に読むのにおすすめ: Codex GPT-5.5 実用ガイド / GPT-5.5 プロンプトガイド / 20 ドル AI スタック


コメント